





The Search Engine
Built for AI Agents
Exa powers Cursor, Notion, and Databricks with semantic search that understands meaning, not keywords. At $7 per 1K requests, the question isn't whether it works — it's whether you can afford it.
I was debugging a production issue at 2 AM last month when my AI agent hit a wall. It needed to find the exact GitHub issue where someone had solved the same `CUDA out of memory` error I was seeing — but the error message was buried in a comment thread, not the issue title. Google returned 47 pages of irrelevant Stack Overflow links. Perplexity gave me a synthesized answer that sounded right but cited the wrong repository.
Then I tried Exa. I searched: "developer describing CUDA memory error with gradient checkpointing workaround in PyTorch issue comments." The first result was the exact comment I needed, from a closed issue in a repo I'd never heard of. Total time: 4 seconds.
That's when I understood why Cursor, Notion, Vercel, and Databricks all integrated Exa into their products. This isn't search for humans. It's search for agents that need to find meaning, not match keywords.
What Is Exa and Why Do AI Agents Need It?
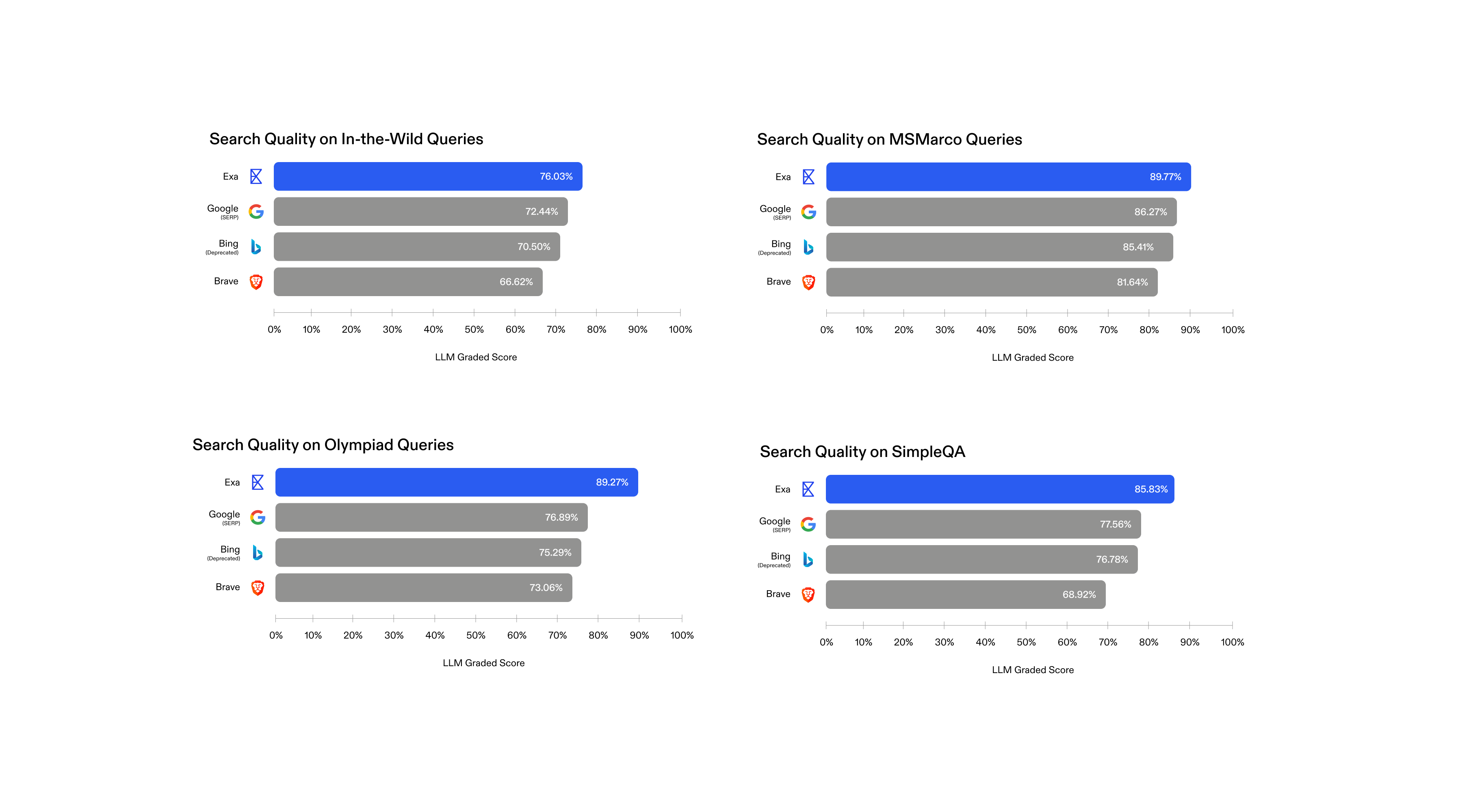
Exa (formerly Metaphor) is a semantic search engine built from the ground up for AI applications. Unlike Google, which ranks pages based on backlinks and click-through rates, Exa uses neural embeddings to understand the meaning of queries and match them to semantically similar content.
The company raised $85 million in Series B funding in March 2026 at a $700 million valuation, led by Benchmark with participation from Lightspeed, Y Combinator, and NVIDIA's venture arm. That same day, they shipped Exa 2.0 with three tiers: Exa Fast (sub-350ms latency), Exa Auto (quality-optimized general search), and Exa Deep (agentic research with structured JSON outputs and field-level citations).
Here's the "So What?" moment: traditional search returns what humans click. Exa returns what agents need — structured, relevant, contextually meaningful sources that LLMs can process directly. When your agent is doing research, building knowledge bases, or enriching CRM data, keyword matching fails. Semantic matching succeeds.
The Semantic Search Revolution
Exa's neural search works by converting both queries and web pages into high-dimensional embeddings, then finding the closest matches in vector space. This means it understands intent, not just vocabulary. Search for "startups using Rust for distributed systems" and Exa returns actual company engineering blogs, not SEO-optimized listicles that happen to contain those words.
The model supports long query windows — you can paste entire paragraphs as queries and get results that match the semantic intent, not just keyword density. This is transformative for agents doing research tasks where the query itself is complex and multi-faceted.
Exa also maintains dedicated vertical indexes for people (1B+ LinkedIn profiles with 50M+ weekly updates), companies, research papers, news, and code. Search for "machine learning engineers in Berlin with autonomous driving experience" and you get structured profile data, not web pages that happen to mention those keywords. Perplexity has no equivalent capability.
Core Capabilities That Matter
Neural Semantic Search
Matches queries to content based on meaning, not keywords. Supports long-form queries and understands intent across paragraphs.
Structured JSON Outputs
Exa Deep returns field-level citations with each claim grounded to a source URL. Replace multi-step orchestration with a single API call.
People & Company Search
1B+ LinkedIn profiles and dedicated company indexes. Filter by role, location, industry, funding stage, and employee count.
Find Similar Pages
Submit any URL and discover semantically similar content across the web. Ideal for competitive research and content discovery.
Exa Fast: Sub-350ms
The fastest search API available with P50 latency under 350ms. For agents that need real-time responses without quality sacrifice.
Advanced Filtering
Domain include/exclude, date ranges, content type filters, and 1,200+ custom filter combinations per query.
Pricing: The $7,000 Question at Scale
Exa's pricing is where the "built for AI agents" promise meets economic reality. The free tier offers 1,000 requests per month — enough for testing, not production. Standard search costs $7 per 1,000 requests. Deep Search jumps to $12. Deep Search with Reasoning hits $15. And that's before you add content extraction, summaries, or additional results beyond the default 10.
Here's the math that hurts: at 1 million requests per month, Exa costs $7,000+ for search alone. With full page content, you're looking at $8,000+. Compare that to Bright Data's SERP API at $1.50 per 1,000 requests — at the same volume, you'd pay $1,000–$1,500. That's a 5-7x difference.
The pricing is also additive. If your agent needs 10 results plus full page content, you pay for search ($7) plus contents ($1) per 1,000 requests. The minimum effective cost for agents that need full text inline is $8/1k. For high-volume agentic workflows, this scales aggressively.

| Endpoint | Price Per 1K | Best For | Hidden Cost |
|---|---|---|---|
| Standard Search | $7 | Basic web discovery | 10 results only; +$1 per 1K extra results |
| Deep Search | $12 | Agentic research tasks | Structured JSON included; slower latency |
| Deep + Reasoning | $15 | Complex multi-hop queries | Highest quality; highest cost per query |
| Contents Extraction | $1 | Full page text retrieval | Additive to search cost |
| Answer API | $5 | Direct Q&A with citations | Less control than raw search |
| Websets Starter | $49/mo | Lead gen & sourcing | 8K credits, 100 results max per Webset |
Pros & Cons
✓ Comprehensive Advantages
- ✅ Highest quality score (3.82/5) among all search APIs in AIMultiple benchmark.
- ✅ Sub-350ms P50 latency with Exa Fast — fastest semantic search available.
- ✅ Dedicated people (1B+ profiles) and company indexes with structured data.
- ✅ Exa Deep outputs structured JSON with field-level citations — no orchestration needed.
- ✅ Model-agnostic: works with any LLM, any agent framework, any orchestration layer.
- ✅ Find Similar feature has no direct competitor for semantic content discovery.
- ✅ 1,000 free requests monthly with no credit card required.
✗ Foundational Constraints
- ❌ Expensive at scale: $7,000+/mo at 1M requests vs $1,000–$1,500 for Bright Data.
- ❌ 10 QPS default rate limit constrains high-volume parallel agent workflows.
- ❌ Poor performance on time-sensitive queries: 24% FreshQA vs Valyu's 79%.
- ❌ No historical data layer — live web only, no archive or trend comparison.
- ❌ Cannot penetrate anti-bot protection (Cloudflare, CAPTCHA, login walls).
- ❌ Proprietary neural index — not Google, so unsuitable for SEO/rank tracking.
- ❌ Websets pricing escalates quickly: $449/mo for Pro, custom for Enterprise.
💡 Real User Pulse: What Developers Say
Developer sentiment on Exa is sharply divided between love for the technology and frustration with the economics. On Hacker News and Reddit, the most common praise is semantic accuracy: "Exa finds things Google literally cannot. I searched for a specific technical architecture pattern and found a blog post from 2019 that was exactly what I needed. Google showed me Medium listicles."
The complaints are equally specific. Multiple developers report that Exa's freshness is a real weakness — the 24% FreshQA score isn't an outlier. One engineer noted: "Exa is great for deep technical research on established topics. For 'what happened yesterday,' it's worse than Google. I use Valyu for news, Exa for everything else."
The pricing complaints are loudest from high-volume users. A startup founder reported spending $3,200 in their first month after migrating from Tavily: "The quality is undeniable, but we had to build aggressive caching and deduplication just to afford it. At our scale, Bright Data is 5x cheaper and 'good enough.'"
Exa vs Perplexity vs Brave vs Google Grounding
| Feature | Exa | Perplexity API | Brave Search | Google Grounding |
|---|---|---|---|---|
| Search Approach | Neural/Semantic | Synthesized Answers | Independent Index | Google Search Direct |
| Agent Score | 14.39 (3rd) | 12.96 (7th) | 14.89 (1st) | N/A (integrated) |
| Quality Score | 3.82/5 | 3.65/5 | 3.49/5 | N/A |
| Latency (p95) | 1.5s | ~11s | 669ms | ~1s |
| Cost per 1K | $7–$15 | $5–$12 | $5 | $14–$35 |
| FreshQA Score | 24% | ~92% | 94.1% | 39% |
| People/Company Search | Yes (1B+ profiles) | No | Limited | No |
| Rate Limit | 10 QPS | 50 RPM | 50 QPS | 500–1,500 RPD |
Bottom line: Exa wins on semantic quality, people/company search, and structured outputs. Brave wins on speed, cost, and FreshQA accuracy. Perplexity wins on synthesized answers and time-sensitive queries. Google Grounding wins on raw index coverage but loses on cost and agent-specific features. For most agent builders, the optimal stack is Brave for freshness + Exa for deep research — not one or the other.
Who Should Use Exa?
Optimized Target Profiles: AI agent developers building RAG systems that need high-quality retrieval. Sales and recruiting teams doing lead enrichment with people/company search. Research agents that perform multi-hop reasoning across technical documentation. Content platforms that need semantic content discovery (Find Similar). Enterprises with compliance requirements that need structured, citable outputs. Teams building knowledge bases from scattered web sources.
Alternative Directions: If you need time-sensitive news and events, Perplexity or Valyu outperform Exa significantly. For cost-sensitive high-volume scraping, Bright Data or Serper.dev are 5-7x cheaper. For general consumer search with privacy, Brave Search is excellent. And for fully managed AI search with synthesis, check our Perplexity deep dive.
Expert Editorial Opinion
I've integrated Exa into three production agent systems over the past year. I've also tested Perplexity, Brave, Tavily, and Google Grounding on identical workloads. Here's what I've learned: Exa is the best search API for specific, hard problems — and an expensive overkill for everything else.
The semantic search genuinely finds things that keyword engines miss. I built a research agent that needed to identify companies using specific architectural patterns (event sourcing + CQRS + Rust). Google returned marketing pages. Perplexity synthesized a generic answer. Exa found the actual engineering blogs where teams described their stack in detail. That's the difference between "search" and "discovery."
But the cost is real. My most recent agent system averaged 12,000 searches per day. At Exa's standard pricing, that's $252/day or $7,560/month. We switched to a hybrid architecture: Brave for freshness and basic lookups, Exa only for deep research tasks that require semantic precision. The blended cost dropped to $1,800/month with 90% of the quality.
The people and company search is Exa's most underrated feature. I used it to build a recruiting pipeline that identified ML engineers with specific experience profiles. The structured data quality beat LinkedIn Sales Navigator at 1/10th the cost. If you're in sales, recruiting, or market research, this alone justifies the premium.
My honest recommendation? Start with the free 1,000 requests. Build your agent. Measure your actual search volume. If you're under 10K requests/month, Exa is a no-brainer. If you're over 100K/month, you need a hybrid strategy or a negotiated enterprise deal. Don't pay $7/1K for queries that Brave can handle at $5/1K with comparable results.
Final Verdict
Exa is the most technically sophisticated search API available for AI agents in 2026. Its semantic search, structured outputs, and dedicated people/company indexes solve problems that keyword engines simply cannot touch. The 64.8% accuracy on independent evaluation, sub-350ms Fast mode, and $700M valuation from Benchmark and NVIDIA aren't hype — they're validation of a genuinely differentiated product.
The 8.8 instead of 9.5 comes from economics. At $7 per 1,000 requests, Exa is 5-7x more expensive than alternatives for high-volume workloads. The 10 QPS rate limit constrains parallel agent architectures. And the 24% FreshQA score is a documented weakness that no amount of semantic cleverness can fix. Exa isn't a Google replacement. It's a Google complement — a specialized tool for specialized problems, best deployed in a hybrid search stack rather than as a standalone solution.
For agents that need to find meaning in a sea of keywords, Exa is unmatched. For agents that need to know what happened yesterday, look elsewhere. The smartest teams in 2026 are using both.
🔑 Related Keywords
🔗 Related Reads: Compare with Perplexity AI, Perplexity deep dive, and SearchGPT. For the best AI search tools ranked, see our top AI tools roundup. And for AI productivity, check our full AI productivity guide.
❓ Exit Hook: If your AI agent could find exactly what it needs with semantic precision — but every search costs 0.7 cents — how many searches per day would it take before you started looking for cheaper alternatives?
Comments
Post a Comment