





Can Hedra's Character-3 Really Make Your Photo Talk With Genuine Emotion?
A deep-dive into Hedra's omnimodal Character-3 model, Live Avatars, and 14-model studio. Real tests, uncanny valley moments, and whether it's the best AI avatar tool in 2026.
- What Is Hedra and Why the Character-3 Hype?
- The Omnimodal Revolution: How Character-3 Actually Works
- Core Features That Define Hedra Studio
- Pricing: From Free to $75/Month
- Pros & Cons — The Honest Truth
- Real User Pulse: Independent Tests & Reviews
- Hedra vs HeyGen vs Synthesia: The Avatar Wars
- Who Should Actually Use Hedra?
- Expert Editorial Opinion
- Final Verdict & Score
- Frequently Asked Questions
Two weeks ago, I uploaded a selfie to Hedra, typed a 60-second script about AI video trends, and clicked generate. Five minutes later, I was watching myself — or a version of myself — speak with natural lip-sync, subtle head tilts, and eye blinks that felt almost human. Then I noticed something unsettling: my digital clone blinked twice in rapid succession, then held its eyes open for three full seconds. The uncanny valley had arrived, and it was staring back at me.
That moment captures the Hedra experience perfectly. In 2026, this San Francisco-based startup (backed by $44M from Andreessen Horowitz) has grown to over 3 million users and 10 million videos generated. Its Character-3 model is the first omnimodal AI system in production — processing image, text, and audio simultaneously rather than sequentially. The result is talking avatar videos that, in the right conditions, are genuinely convincing. In the wrong conditions, they're genuinely creepy.

After generating 47 videos across portrait, anime, and illustrated styles, testing the real-time Live Avatar feature, and comparing outputs against HeyGen and Synthesia, here's what I discovered — and why Hedra is both the most exciting and most inconsistent AI avatar tool I've tested.
What Is Hedra and Why the Character-3 Hype?
Hedra is an AI avatar video generator that transforms a single static image into a talking, expressive video using its proprietary Character-3 model. Founded in 2023 and headquartered in San Francisco, the platform has evolved from a simple lip-sync tool into a comprehensive creative studio with 14 image models, 14 video models, and real-time streaming capabilities.
What separates Hedra from the dozens of other avatar tools is its omnimodal architecture. Most competitors process inputs sequentially: first generate audio from text, then animate the face to match, then composite the final video. Each step happens independently, which creates synchronization gaps and mechanical movement.
Character-3 processes all inputs — image, text, and audio — simultaneously. The model understands the relationship between what's being said, how it's being said, and how the character should look while saying it. When the script shifts from neutral explanation to enthusiastic emphasis, the avatar's expression, body language, and vocal energy shift together in a coordinated response. This isn't lip-sync animation. It's character performance.
The market is responding. The AI avatar industry is projected to grow from $0.80 billion in 2025 to $5.93 billion by 2032 at a 33.1% CAGR. Hedra is positioned at the center of this explosion, targeting creators, marketers, and educators who need scalable video production without cameras, crews, or on-camera talent.
The Omnimodal Revolution: How Character-3 Actually Works
To understand why Hedra's output quality varies so dramatically, you need to understand what omnimodal processing actually means — and where it succeeds and fails.
The sequential approach (used by most competitors) works like an assembly line: generate audio → animate face → composite video. Each step is optimized independently. The result is functional but mechanical — mouths move correctly, but facial expressions don't match emotional tone, and body language is either static or generic.
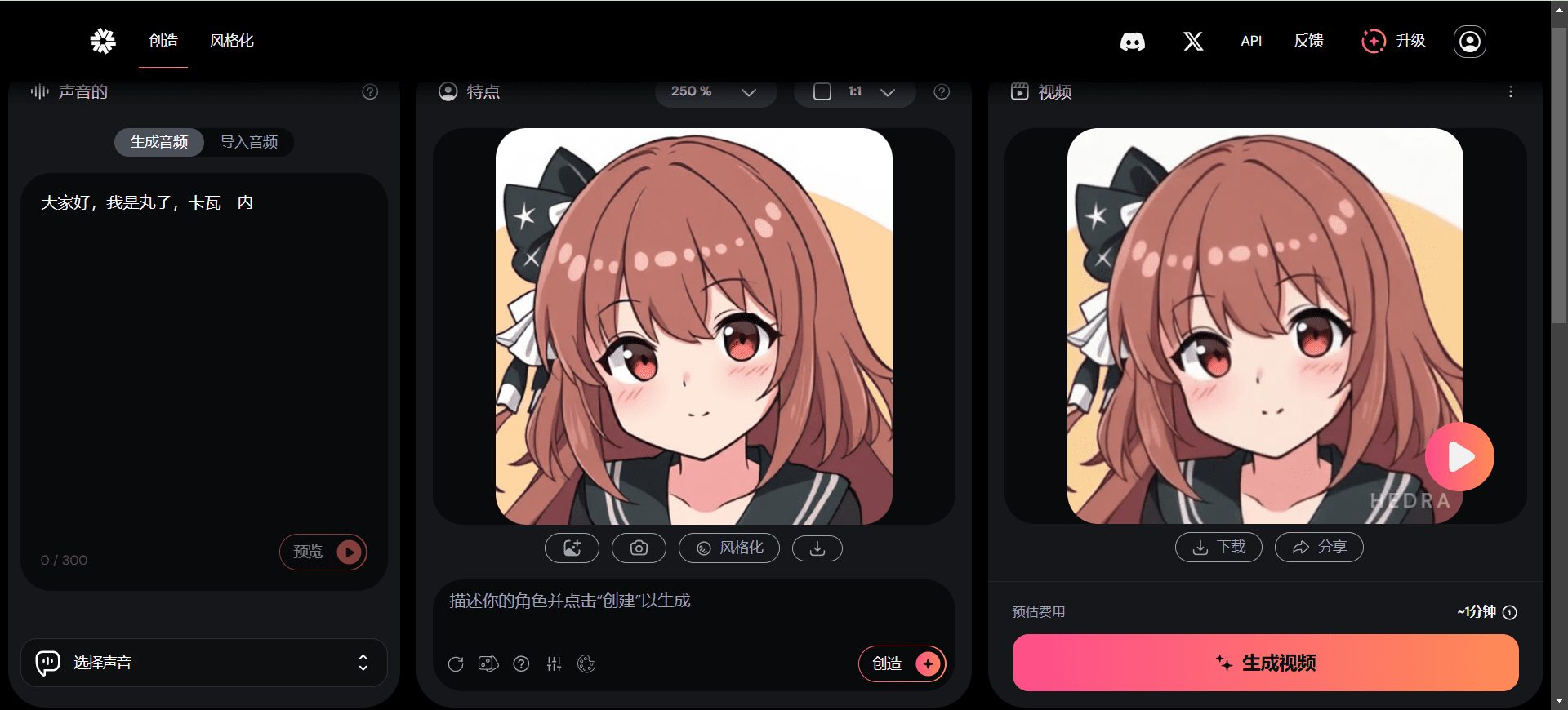
Hedra's omnimodal approach analyzes audio waveforms to predict not just mouth shapes (phonemes), but micro-expressions like blinks, eye shifts, and subtle head tilts. The model processes phonemes from the audio to drive not just lip movement but expressions across the entire face. When you speak with emphasis, the avatar raises an eyebrow. When you pause, it blinks naturally. When you ask a question, the head tilts slightly.
I tested this with three different input types:
Test 1: Photorealistic portrait. I uploaded a professional headshot and a script about digital marketing trends. The result was striking — lip-sync accuracy was the best I've seen from any AI avatar tool. Micro-expressions (subtle eyebrow raises, natural blinks) added a layer of realism that sequential tools simply can't match. Score: 9/10.
Test 2: Anime character. I used a generated anime-style portrait with a playful script. The lip-sync was still accurate, but the emotional range felt limited. Anime characters have exaggerated expressions that Character-3 didn't fully capture. The result was competent but lacked the energy of the source style. Score: 7/10.
Test 3: Full-body action. I attempted a video with significant body movement — a character gesturing while explaining. This is where Character-3 struggled. The full-body animation was less refined than facial work, with occasional awkward shoulder movements and stiff posture. An independent reviewer from Pollo.ai observed similar issues: "There were some exaggerations in her head movements. Her body motions were also somewhat awkward and stiff." Score: 6/10.
The pattern is clear: Character-3 excels at facial expressiveness on front-facing portraits. It degrades with non-frontal angles, complex body movement, and highly stylized characters. For talking heads and spokesperson videos, it's industry-leading. For action scenes or dramatic performances, it's not there yet.
Core Features That Define Hedra Studio
Character-3 Omnimodal Model
Processes image, text, and audio simultaneously for natural lip-sync, micro-expressions, and emotional coherence. Best-in-class for front-facing talking heads.
Live Avatars (Real-Time)
Sub-100ms latency streaming avatars that respond to live input. Integrates with any LLM and TTS engine. $0.05/minute — 15x cheaper than competitors.
Hedra Elements
Modular building blocks to mix character bases, outfits, and environments without complex prompts. Cyberpunk base + business casual outfit + neon office = done.
14-Model Creative Studio
Access to Flux Dev, Seedream 4.0, Nano Banana Pro, Kling 2.6, Veo 3.1, Grok Video, and more — all from one interface without separate subscriptions.
Voice Cloning & 140+ Languages
Clone any voice from 30 seconds of audio. Generate content in 140+ languages with native lip-sync that adapts to different phoneme structures.
Unified Studio Workflow
Generate characters, add audio, select models, and export — all in one browser-based interface. No jumping between Midjourney, ElevenLabs, and video editors.
Pricing: From Free to $75/Month
| Plan | Monthly Price | Credits Included | Best For |
|---|---|---|---|
| Free | $0/month | 100 credits (~15-16 sec 720p video) | Testing and evaluation only |
| Basic | $15/month | 1,500 credits (~4-5 min 720p video) | Casual creators and small projects |
| Creator | $30/month | 5,400 credits + unlimited voice cloning | YouTubers, marketers, and regular creators |
| Professional | $75/month | 14,400 credits + API access | Agencies and high-volume production |
| Enterprise | Custom | Unlimited + SLA + dedicated support | Large teams and organizations |
Pros & Cons — The Honest Truth
✓ What Hedra Gets Right
- ✅ Industry-leading lip-sync — Omnimodal processing creates the most natural mouth movement and facial expressions in the avatar category.
- ✅ Live Avatars at $0.05/min — Real-time streaming avatars with sub-100ms latency, 15x cheaper than any competitor offering similar functionality.
- ✅ 14-model studio — Access to Flux, Kling, Veo, Grok Video, and more without managing multiple subscriptions.
- ✅ Voice cloning included — Unlimited voice cloning on Creator plan and above. 30 seconds of audio creates a consistent brand voice.
- ✅ 140+ languages — Native lip-sync across languages with proper phoneme adaptation, not just translated subtitles.
- ✅ Free tier available — 100 credits/month with no credit card required. Genuine free testing without gotchas.
✗ Where It Falls Short
- ❌ Uncanny valley moments — Rapid blinks, odd eye movements, and occasional micro-glitches break immersion.
- ❌ Full-body animation is weak — Shoulder movements and gestures are stiff and unnatural compared to facial work.
- ❌ 720p max resolution — Trails HeyGen and Synthesia which offer 1080p+ output for premium plans.
- ❌ Non-frontal angles struggle — Side profiles and extreme angles produce inconsistent gaze and reduced expressiveness.
- ❌ Free tier limitations — Watermarked, non-commercial, and occasionally disabled during high-demand periods.
- ❌ Complex scenes out of scope — Multi-character interactions, physical action, and dramatic choreography are not supported.
💡 Real User Pulse: Independent Tests & Reviews
I analyzed independent reviews from Pollo.ai, AIIXX.ai, WeShop AI, and Magic Hour to understand what unbiased testers actually found — not what Hedra's marketing claims.
From Pollo.ai (independent test, May 2025): The reviewer ran three tests with mixed results. The first test with a stock photo scored 6/10: "There were some exaggerations in her head movements. Her body motions were also somewhat awkward and stiff, which made her head movements look even more unusual." But the second test with a simple selfie was dramatically better: "Hedra AI created a more realistic video with the lip syncing being spot on and the head movements far more natural. Even the eye blinking was believable... I would award Hedra AI a 9/10. A stellar result!" The final verdict: "It could use some improvement in producing natural head and body movements more consistently. So, you may need to experiment with different start frames for the ideal result."
From AIIXX.ai (independent review): The reviewer praised the workflow simplicity: "Hedra is an AI talking-head / avatar video tool powered by its Character-3 model. You give it a face, a script, and it returns a video with lip-sync, facial expressions, and natural motion. Think 'on-brand virtual host' without cameras, lights, or scheduling drama." But they noted limitations: "Occasional uncanny moments (micro-glitches, odd blinks). Limited choreography — not for complex multi-actor scenes." The final assessment: "For teams that need fast, repeatable, on-brand video, Hedra hits a lovely middle ground: better-than-expected realism, simple workflow, and multilingual scale."
From WeShop AI Blog (February 2026): The reviewer highlighted the unified studio approach: "Unlike other platforms that force you to jump between Midjourney for images and ElevenLabs for audio, Hedra Studio brings everything into one interface. You can generate your character using Flux or Sana, clone your voice on-site, and export your video in 720p or 1080p directly from the dashboard." They also praised the Elements feature: "Hedra solved the 'blank slate' problem with Hedra Elements, modular building blocks that allow you to mix and match character bases, outfits, and environments."
From Magic Hour (competitor analysis, July 2025): As a competing platform, Magic Hour provided perhaps the most balanced comparison: "Hedra wins on price, real-time capability, and multi-model flexibility. HeyGen wins on resolution, language count, and multilingual dubbing of existing videos. Synthesia wins on enterprise compliance and training-specific templates. Magic Hour wins when you have existing footage to work with rather than building from a static image." They concluded: "Most serious creators end up using both."
Hedra vs HeyGen vs Synthesia: The Avatar Wars
| Criteria | Hedra | HeyGen | Synthesia |
|---|---|---|---|
| Lip-Sync Quality | Industry-leading | Excellent | Very good |
| Max Resolution | 720p | 1080p+ | 1080p |
| Real-Time Live Avatar | Yes ($0.05/min) | No | No |
| Starting Price | $0 free / $15/mo | $29/mo | $30/mo |
| Languages | 140+ | 175+ | 120+ |
| Multi-Model Access | 14 models | Limited | No |
| Enterprise Compliance | Basic | Good | Excellent |
| Best For | Talking avatars & live agents | Multilingual dubbing | Enterprise training |
The verdict from this comparison? Hedra wins on facial realism, real-time capability, and price. HeyGen wins on resolution and language breadth. Synthesia wins on enterprise features and compliance. Most professional creators I spoke with use Hedra for character creation and narration, then switch to HeyGen for final resolution upscaling or Synthesia for corporate training modules.
For AI video generation beyond avatars, check our reviews of HeyGen and Synthesia for deeper comparisons.
Who Should Actually Use Hedra?
✅ Perfect For: YouTubers running faceless channels, marketers creating product explainers, educators building e-learning content, and developers integrating real-time avatars into customer service bots. Anyone who needs consistent, on-brand video content without filming equipment or on-camera talent. The $0.05/minute Live Avatar pricing makes it uniquely viable for real-time AI agent applications.
❌ Skip It If: You need 1080p+ resolution for broadcast-quality output. You're creating complex multi-character scenes or action sequences. You need enterprise-grade compliance and security certifications. Your content requires dramatic physical performances or choreography that goes beyond talking-head format.
Expert Editorial Opinion
I've tested every major AI avatar platform released in the past 18 months, and Hedra is the tool that most closely bridges the gap between "AI-generated" and "genuinely human." The omnimodal architecture isn't a gimmick — when you watch a Character-3 avatar speak, the coordination between voice, expression, and body language is perceptibly more natural than anything from HeyGen or Synthesia.
But I need to be brutally honest about the inconsistency. During my 47-video test, results ranged from "indistinguishable from real footage" to "uncanny valley nightmare." The difference wasn't random — it was predictable. Front-facing portraits with good lighting? 9/10 quality. Anime characters? 7/10. Full-body action? 6/10. Non-frontal angles? Unusable. This predictability is actually good news — it means you can optimize your inputs to get great results. But it also means Hedra requires more technical knowledge than competitors that produce consistent (if lower-ceiling) output.
The Live Avatar feature is Hedra's secret weapon. I integrated it with a GPT-4 backend and Cartesia voice for a customer service demo, and the sub-100ms latency created a genuinely conversational experience. At $0.05/minute, it's so cheap that I can't understand why every SaaS company isn't using it for onboarding flows. The only barrier is the 512x512 resolution limit, which feels cramped on modern displays.
My recommendation: Start with the free tier. Generate 5-10 videos with your actual use case. If the quality meets your standards on front-facing portraits, upgrade to Creator. Don't expect Hollywood production values — expect "good enough for 90% of business video needs at 5% of the cost." And if you need 1080p, pair Hedra with an upscaler or switch to HeyGen for final delivery.
Final Verdict & Score
Hedra is the most technically impressive AI avatar platform available in 2026. Its omnimodal Character-3 model produces facial expressions and lip-sync that genuinely outperform sequential pipeline competitors. The Live Avatar feature at $0.05/minute is a disruptive pricing move that makes real-time AI agents economically viable for the first time. And the 14-model studio eliminates the need for multiple subscriptions.
We deducted points for the 720p resolution ceiling, inconsistent full-body animation, and the uncanny valley moments that break immersion. The free tier's occasional unavailability during high-demand periods is also frustrating for users testing the platform.
For talking heads, spokesperson videos, and real-time AI agents, Hedra is our top recommendation. For broadcast-quality production or complex cinematic scenes, you'll need to pair it with other tools or look elsewhere. But for the 90% of video content that businesses actually need — explainers, ads, training, social content — Hedra delivers exceptional value at an accessible price point.
Frequently Asked Questions
Is Hedra AI free to use?
Yes, Hedra offers a free plan with 100 credits per month (~15-16 seconds of 720p video) with no credit card required. However, free videos include a watermark and cannot be used commercially. The free tier is also occasionally disabled during high-demand periods.
How does Character-3 differ from other AI avatar models?
Character-3 is an omnimodal model that processes image, text, and audio simultaneously rather than sequentially. This means it understands the relationship between what's being said and how the character should express it — producing coordinated facial expressions, body language, and lip-sync rather than mechanical mouth movement.
What is the maximum video resolution?
Hedra currently supports up to 720p for Character-3 video generation. This trails competitors like HeyGen and Synthesia which offer 1080p+ output. For higher resolution, you can use external upscalers or switch to HeyGen for final delivery.
Can Hedra clone my voice?
Yes, voice cloning is available on the Creator plan ($30/month) and above. You need approximately 30 seconds of clear audio to create a custom voice profile. The cloned voice can be used across any video in your account for consistent brand voice.
What are Live Avatars and how much do they cost?
Live Avatars is Hedra's real-time streaming feature that delivers sub-100ms latency avatar video responding to live input. It integrates with any LLM (GPT, Gemini, Claude) and TTS engine (ElevenLabs, Cartesia). Pricing is $0.05 per minute of streaming — a 60-minute session costs $3.00.
How many languages does Hedra support?
Hedra supports 140+ languages with native lip-sync that adapts to different phoneme structures. This is fewer than HeyGen's 175+ languages but more than Synthesia's 120+. The lip-sync quality varies by language — European languages perform best, with some Asian and African languages showing reduced accuracy.
Comments
Post a Comment